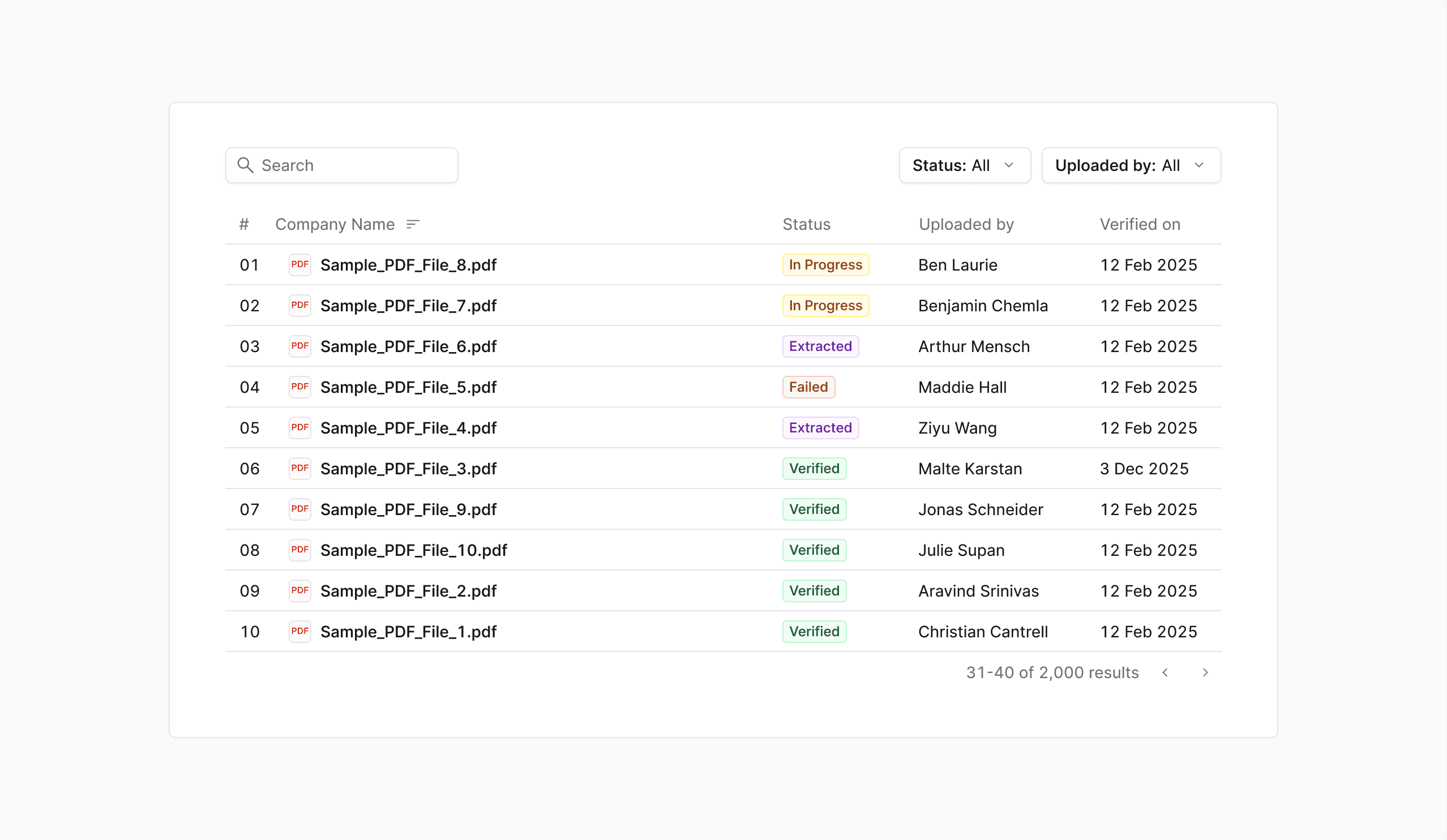
AI-Document Extraction
Designing a fast, transparent, and trustworthy extraction experience for small VC teams, without waiting for the AI to be perfect.
A story of bringing clarity and confidence to an imperfect AI system.
Introduction
Every VC firm I talked to had the same problem. Portfolio companies send financial updates every month. PDFs, spreadsheets, forwarded emails. Each one formatted differently, using different names for the same numbers. And every cycle, an analyst opens each one, finds the right metrics, and manually keys them into a tracker.
That's 2–4 hours per analyst, per cycle. Across 30, 50, 80 portfolio companies. No one thinks of it as a cost because it's just... the job. But it's one of the most expensive things a small VC firm does, and it produces zero strategic value.
The obvious answer is AI extraction. The real answer: extraction models fail constantly on the kind of documents VCs actually receive. And when they fail, they often don't say so, they give you a confident number with no citation, and you have no way to know if it's right. That's not automation. That's a trap.
My challenge was to design a lightweight, reliable extraction experience that users could trust, despite imperfect AI accuracy. I led the UX for this project and helped ship the first version in 10 days.
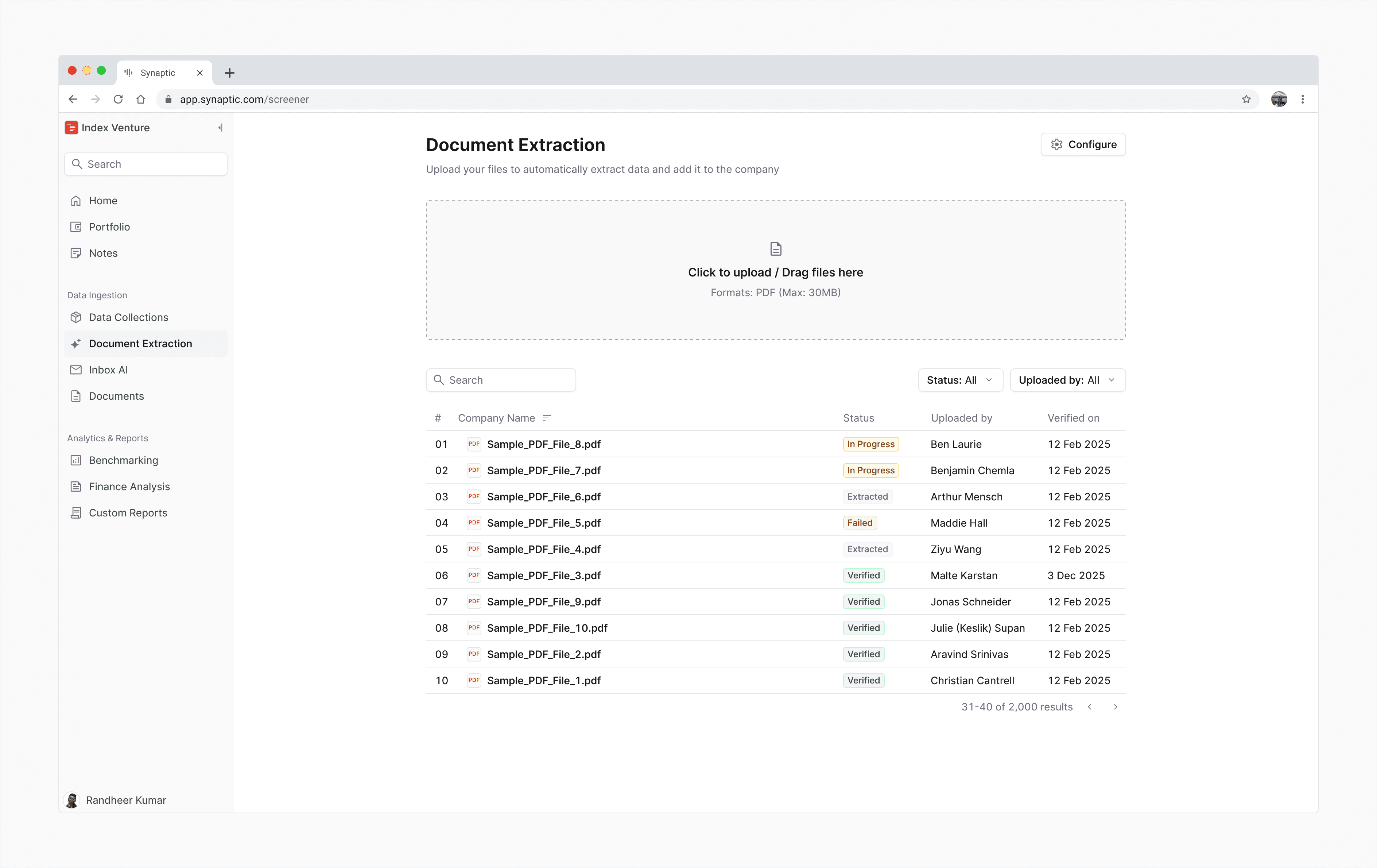
Problem
Small VCs didn't want a full-fledged extraction service. They wanted something simple, fast, and affordable. Manual extraction took too long. Existing tools extracted too much. And users didn't trust AI-generated numbers without transparency or control.
The real problem had three layers, and getting this wrong would have meant building something fast but unusable.
The trust gap
Analysts couldn't verify AI output without re-doing the extraction manually. If checking takes as long as doing, automation provides zero value. This wasn't an attitude problem, it was a design problem. AI tools offered no transparency into where a number came from.
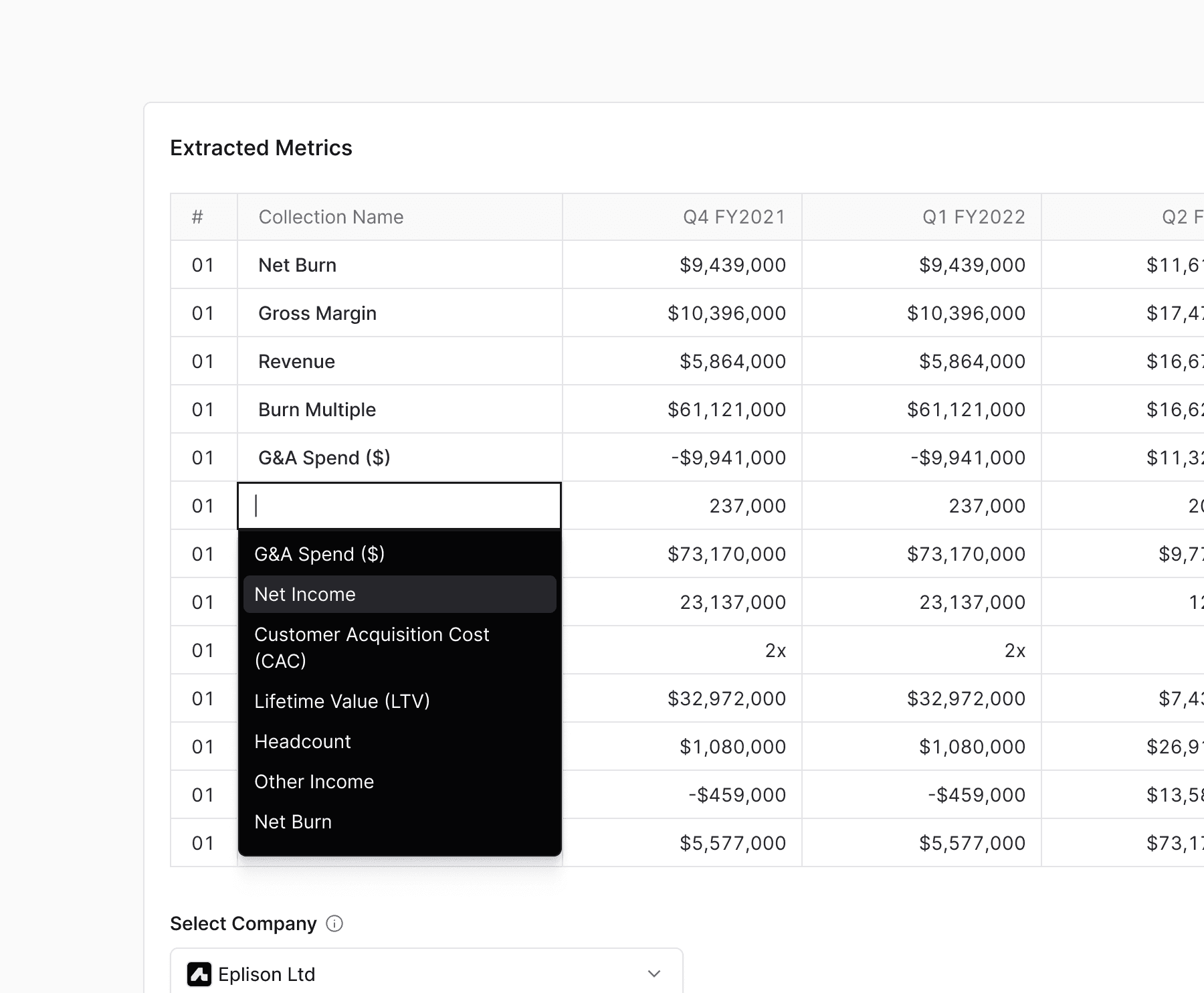
The taxonomy mess
"Revenue" might be "Net Revenue," "ARR (Net)," or just a column header with no label. Any rigid schema breaks immediately on a real portfolio. The system had to handle semantic variety without manual reconfiguration for every document.
The noise problem
Existing tools extracted 60+ fields and dumped everything on the analyst. More output isn't better, it creates cognitive overhead and makes review slower than the original manual work.
"Design a transparent, trustworthy extraction experience, despite inconsistent documents and imperfect AI accuracy."
Research & Context
I had days, not weeks. The founding team had already done deep customer development. I ran targeted follow-ups with two analysts and one senior associate. I was listening specifically for where people described distrust, workarounds, and anxiety. Not what they said they wanted.
Analysts never trusted automated output on first sight
Default behavior was always to re-verify. Trust had to be built into the interaction model, not just claimed in UI copy.
Messy documents weren't edge cases, they were the norm
Quarterly board decks, snapshot emails, CSV exports from accounting software. All required different reading strategies, every cycle.
Wrong numbers had real reputational consequences
Bad data in a fund review meant professional risk. Users would rather do it manually than risk being wrong in front of LPs.
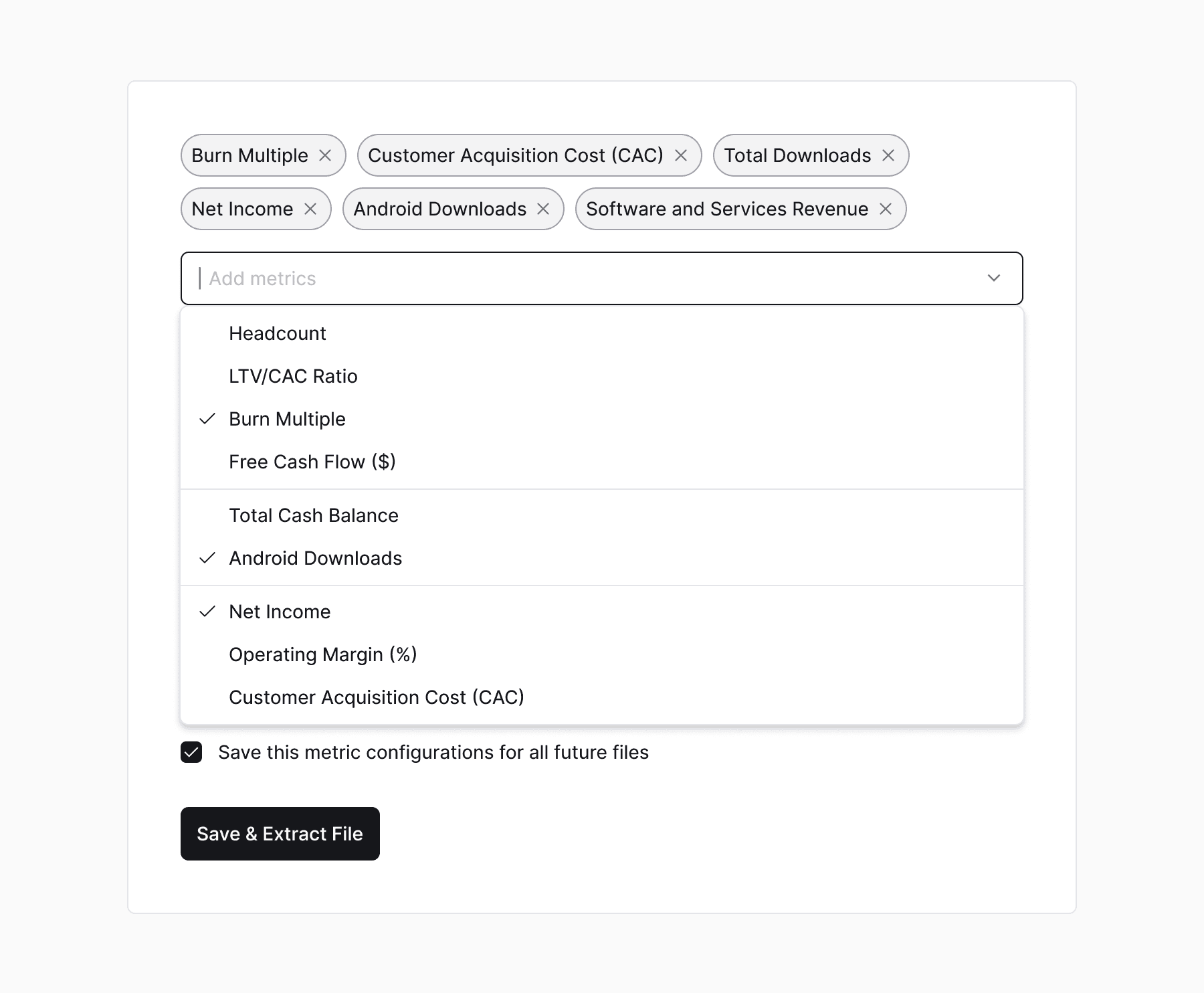
Control matters more than accuracy
Users who could see, inspect, and correct output reported higher confidence, even when raw model accuracy was below 50%. Transparency was doing the heavy lifting.
Research that shaped the design direction
Four sources that directly informed the design decisions, on AI transparency, human-in-the-loop systems, and how trust is built (or broken) in AI-powered workflows.
Research & Context
The extraction model performed at only 29% initially, improving to ~60% after training. We had a ten-day deadline, 100+ non-standardized metrics, and no product manager. Design worked directly with data science, engineering, and founders to define scope.
These constraints led us to design a human-in-the-loop system, where the user always remained in control.
Outcome
We shipped V1 in just 10 days, reducing extraction time from 2–4 hours to under 60 seconds. The editability we built into the experience helped compensate for AI imperfections and gave users the control they needed to trust the output.
As a result, the feature quickly became the strongest differentiator in sales demos and helped onboard early customers with confidence. Not because we promised accuracy. Because we designed for honesty.
Retrospective
We validated the feature internally using 200+ real documents. This helped refine table layouts, metric grouping, and review flow. Even with limited model accuracy, users trusted the system because they could inspect and correct everything.